1. Background and Motivation
Data Transfer Framework (DTF) is an I/O middleware designed for achieving scalable and high-speed data transfer between application components in multi-component workflows. Multi-component workflow is becoming a popular computation model in High Performance Computing (HPC), in which multiple independently developed application components are coupled together to perform more sophisticated and complex computations (e.g. data assimilation based weather prediction system).
In such workflows, massive computation data generated by a component during execution need to be frequently transferred to the other component as the input data to the subsequent computations. However, the implementations of inter-component data exchange in most of the multi-compoenent systems are either based on file I/O through parallel file system or specifically designed coupling softwares. Both of the approaches have pros and cons. Due to the fact that coupled application components are usually developed by different research teams, file I/O became the easiest approach, which exchanges data through file systems using high-performance parallel I/O libraries (e.g. PnetCDF and HDF5). The major drawbacks of file I/O based approach are low speed and inefficiency because the reader components have to wait until the writer component finishes its data writing process. Some existing coupling softwares can be deployed to overcome the mentioned shortcomings of file I/O based data transfer. However, the I/O kernels of existent multi-component systems are required to be largely modified using the dedicated Application Programming Interfaces (APIs) provided by these softwares. Therefore, there exists a pressing need for an easy-to-use approach to minimize the drawbacks mentioned above and transfer massive computation datadata between application components in a scalable and efficient manner.
DTF is such an approach that combines the advantages of file I/O and coupling software, which aims at minimizing the modification of existing I/O kernels in multi-component systems and providing high-speed high-efficiency inter-component data transfer. The current implementation of DTF works with multi-component systems whose inter-component data transfer is built upon Parallel NetCDF I/O (PnetCDF) library. Instead of using file systems, DTF takes full advantage of high-performance interconnects in HPC and transfers data using Message Passing Interface (MPI), which transparently redirects PnetCDF file I/O operations to message passing. A graphical comparison of file I/O and DTF based inter-component data transfer is shown in Fig. 1.
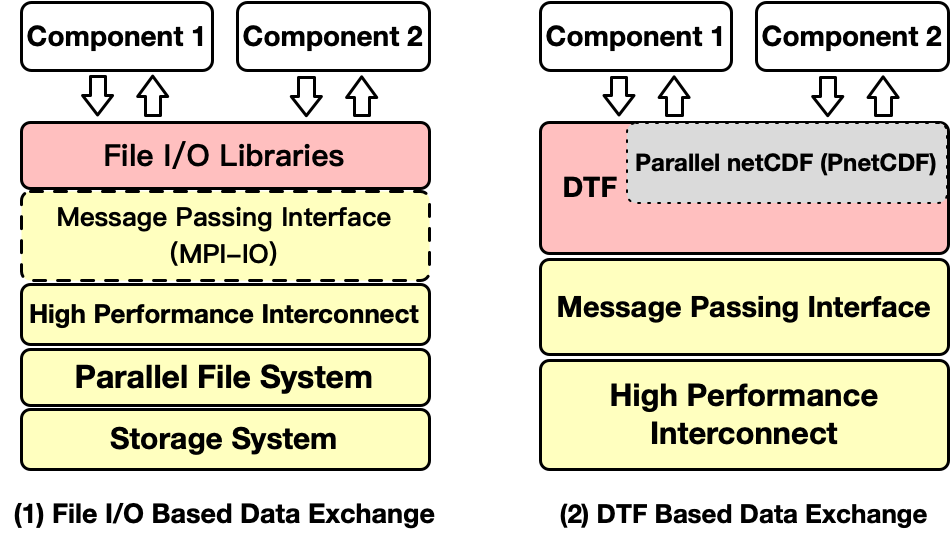
Fig. 1 Difference between File I/O and DTF based inter-component data exchange.
This documentation assumes that the reader has a grasp of the usage of PnetCDF library. An detailed overview of DTF design will be introduced in the next section.
2. Overview of DTF
The original PnetCDF library uses MPI-IO under the hood, which allows multiple processes to write data to the same NetCDF file in parallel. By compiling with the provided DTF-based PnetCDF library, original MPI-IO operations can be transparently redirected to message passing.
Instead of creating a new PnetCDF file on the disk, PnetCDF function calls during each I/O phase, such as ncmpi_open(), ncmpi_def_dim and ncmpi_def_var, which opens a file and defines PnetCDF dimensions and variables respectively, will be intercepted by the DTF library, and the metadata describing the ‘file’ will be stored in DTF data structures.
Intercepted PnetCDF I/O operation calls such as ncmpi_put_var() and ncmpi_get_var() will register each read or write operation as an I/O request object in the DTF library.
Each I/O request object contains the following metadata:
varid: the PnetCDF variable ID;rw_flag: for distinguishing between read and write request;datatype: requested data type;start: corner coordinate of the requested data block;count: length of the requested data block in each dimension;buffer: address of the user buffer.
These collected I/O requests will be further used for matching read requests with their corresponding write requests, which will be introduced in the following subsection.
2.1. I/O Request Matching
I/O request matching is one of the important features in DTF. During execution, designated numbers of processes of the writer component will be delegated to collect all the I/O requests and match each read request against the corresponding write request(s) according to the metadata contained in each request as matcher processes. The number of matcher processes can be adjusted by users.
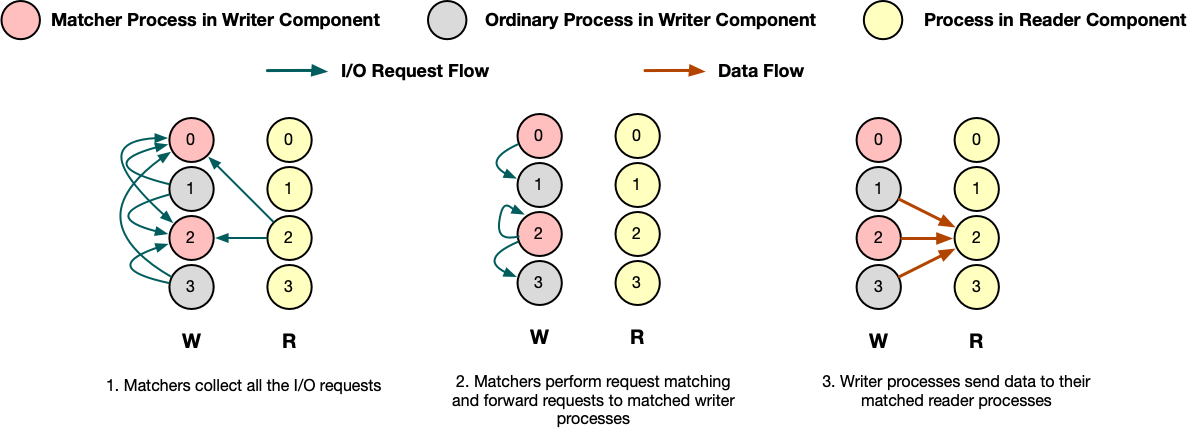
Fig. 2 A request matching example.
For example, there are two matcher processes in the writer component shown in the figure above.
Firstly all the writer processes and reader processes send their I/O requests to the corresponding matcher processes.
Matcher processes then perform request matching based on the start and count metadata contained in each read request and look for the corresponding write requests.
The requested data blocks of each read request may be matched with multiple write requests, each of which will write data to a sub-block of the requested array block.
In this example, the read request of process 2 of the reader component is matched against process 1, 2 and 3 of the writer component.
Once a match is found, the matcher processes will ask the writer process to send the requested data to the matched reader process.
After received the message from the matcher, the writer process will copy the requested data to the send buffer along with the metadata and sends to the reader process.
Once the requested data is delivered, the reader process will unpack the message and copy the data out from receive buffer.
For optimal performance, I/O requests are divided and distributed among the matcher processes. Each of the matchers is delegated to handle the I/O requests of a sub-block of the multi-dimentional variable. There is a trade-off in this approach: request matching in parallel improves performance; However, if there are too many matchers the request may end up being split too many times resulting in more communication between readers and writers. Therefore, users should be responsible to choose the best amount of matchers.
2.2. I/O Replay
Some multi-component workflows contain multiple iteratively executing components with the constant I/O patterns and data size within each iteration, i.e. only the contents of the data blocks are being updated during each iteration. In the latest version of the DTF, an option to record and replay the I/O pattern is introduced as an optimization for such frameworks. How to enable I/O replay will be introduced in the section usage.
When the I/O replay is enabled, during the first iteration, writer processes will store the information about all the request matching results, e.g. source and destination process of each data block. In the subsequent iterations, the I/O request matching phase will be skipped so that all the writer processes can immediately start sending the requested data to the reader processes by following the recorded pattern.
3. Contact Us
If you have any questions or feedback regarding DTF or this documentation please feel free to send emails to our mailing list.
English/Japanese: syssoft-dtf_AT_googlegroups.com (Please replace _AT_ with the @ sign)